
Legos were the best toy growing up. A box of a hundred little plastic pieces gave you the raw materials necessary to build anything imaginable (once you realized you didn’t have to follow the instructions).
The crux of the brilliance of this toy was in the interoperability of all the pieces – as long as it had that little Lego nub on it you knew it would always snap perfectly together with any of the other pieces.
At age eight this would be my first lesson in the value of modular design.
Recently I’ve noticed a pattern in forums of the major workflow automation tools in which people are wrestling with how to tame the chaos of these massive workflows with unwieldy, sprawl of parts copy/pasted in multiple locations all doing slightly different things. Each tool has a different answer for handling this problem but I’m going to propose a common “Lego nub” here – a technique that works identically across all tools and has two key advantages over the other proprietary approaches in the form of interoperability and ease of debugging. But first let’s look at why any of this even matters.
The problem with forsaking modularity
If you’re just knocking out a one-off, quick & dirty solution to a problem and don’t care about maximizing readability, maintainability, extensibility & reusability then disregard everything I’m about to tell you and continue building however is most intuitive for you. But if you’re starting a project that will grow in complexity over time, needs to evolve to accommodate future unforeseen requirements and will at some point be maintained by others, it’s worth it to go into the weeds a bit here to learn this technique.
When you neglect modular architecture as your app grows you wind up with bugs, difficulty of maintenance, poor readability and replication of functionality in multiple locations which makes it difficult to work on. And these problems compound as complexity increases so your application eventually will eventually reach a critical point beyond which it becomes impossible to work with. I’ll show you an example in a minute but basically:

The good news is designing with modularity in mind up front is not that difficult. It just requires refraining from hitting copy/paste when you need to replicate functionality and ask the question “can I black-box this piece in such a way that it can be used elsewhere?” Let’s look at a real example to make this all more concrete.
The workflow image below is taken from this thread in the Make forums. I found countless other examples here here here here here here here here here and here but let’s just go through this one. The original poster knew instinctually there was a better way. His words “it has a lot of end points that all do the same thing” and “I feel like this could be consolidated … in some way which would also make editing way easier in the future.” And he’s absolutely right. We don’t even have to drill into the logic here, what do you notice composition-wise about this image?
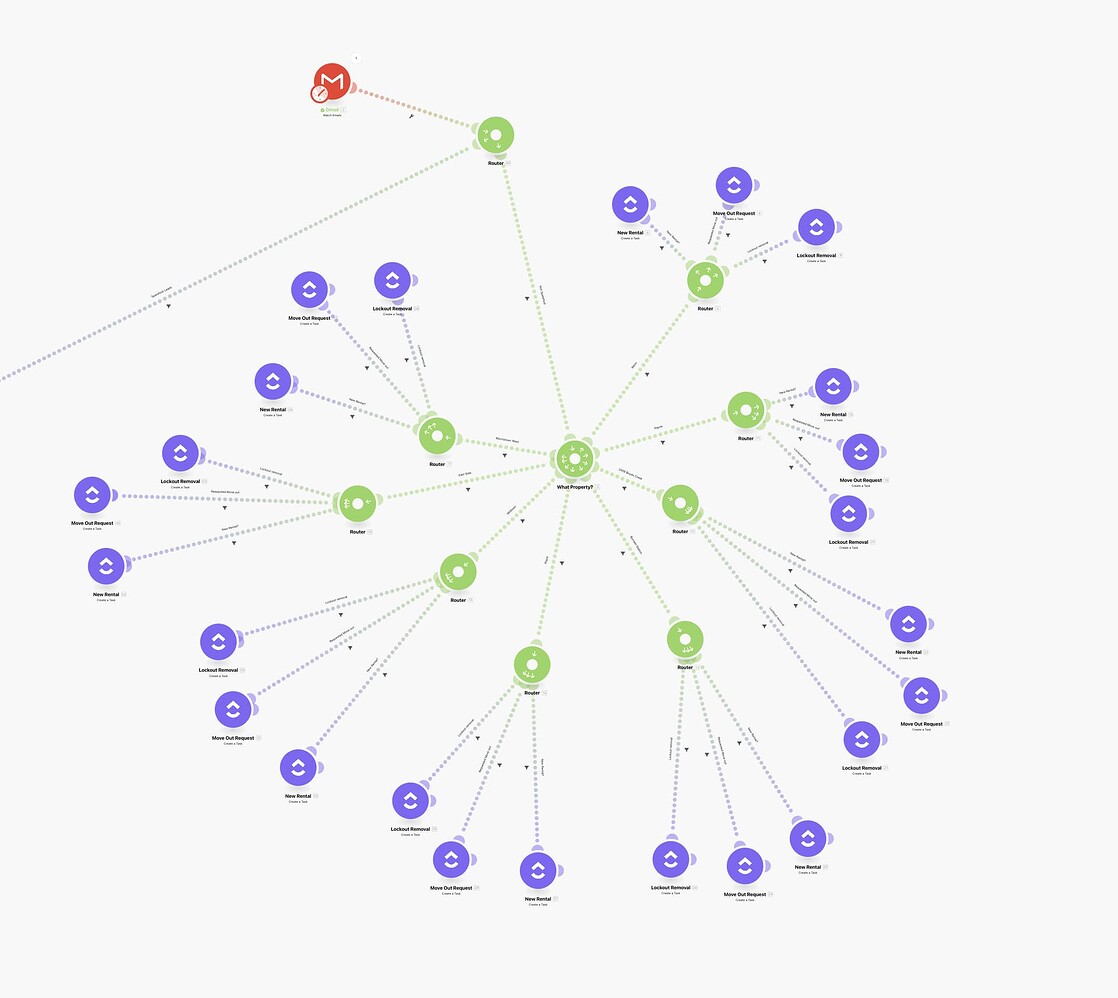
Answer: it looks like a fractal pattern or an organism with cells dividing. You can see replication at two different levels with the green “branch” nodes and the purple “leaf” nodes sprouting from those, exactly three each identical in name. When you see this kind of systemic fractal duplication it’s a huge clue that we can probably refactor this and collapse it into a very simple set of modular workflows.
Two principles from software engineering help us here: “DRY (don’t repeat yourself)” and “encapsulate the variance.” DRY is how we identify the candidate portion ripe for abstraction and “encapsulate the variance” is how we perform that abstraction. Simply ask the question, “Where is the repetition in the structure here and can we turn that into a variable to handle it with fewer moving parts?”
In this particular case this workflow is an automation responsible for checking the email inbox of a realtor and performing automated email followup with their client based on two questions: “Which type of property is it?” and “Which type of problem are we dealing with?” So…. those become our two variables. This whole intricate monolithic workflow can be collapsed into three simple separate modular workflows:
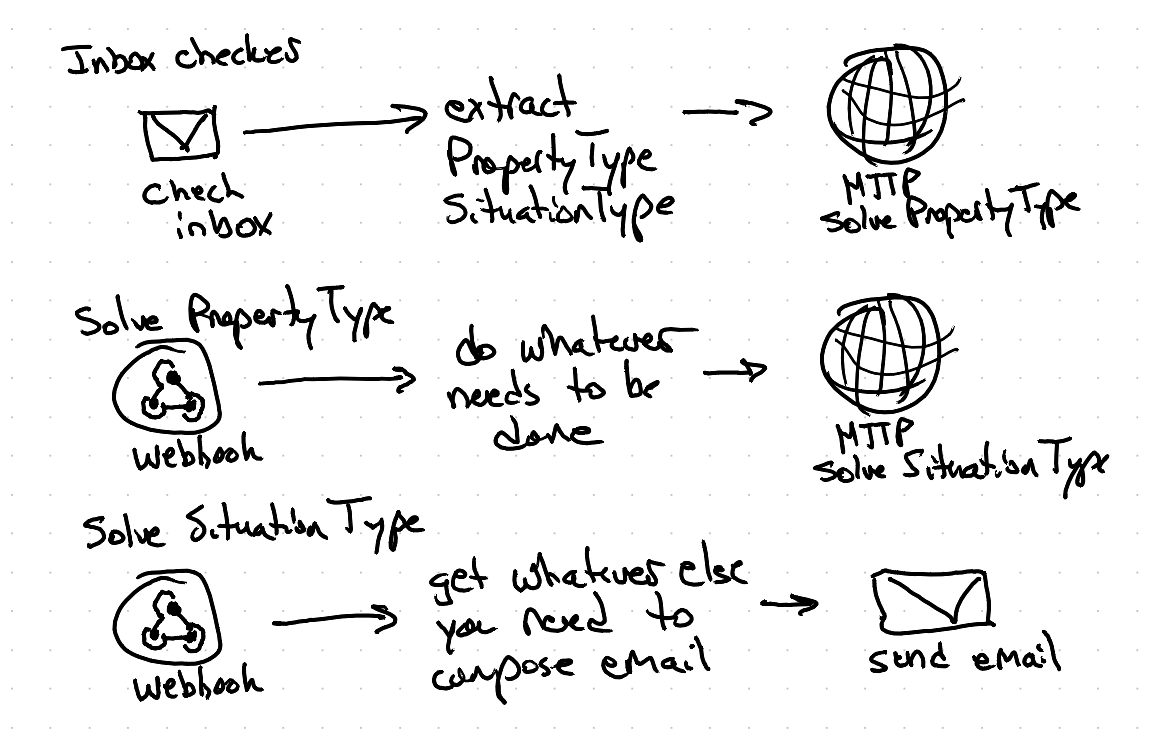
And now instead of 24 different nodes each sending the email message you have a single place that handles the sending of the email. If the need arises to start bcc’ing legal on that email message we make that change in one place as opposed to 24 places. And imagine if we needed to then support alternate forms of messaging beyond email like say SMS and WhatsApp… you’d be looking at maintaining 72 leaf nodes with the old approach vs. one under the modular approach. And how about the mushrooming complexity if you needed to then add an extra followup step on each of the 72 nodes to tag the email recipient in your CRM… 🤯 You’re now seeing how this can rapidly spin out of control into an impossible sprawling mess.
So why use HTTP Request + Webhook?
You might say, Make.com has a solution for this already, why not use their “Scenario inputs” feature to call a sub workflow?
Or if you’re using Zapier why not its Sub Zap concept?
Or in n8n why not use its sub workflows?
There are two compelling reasons why sticking with a simple HTTP Request & Webhook is advantageous.
Reason #1: Interoperability
HTTP Post is the ultimate “Lego nub” in that it’s an Internet standard that can be spoken by any application. “So what?” you say… What if you’ve built your complex workflow in Make.com’s tool and now you determine maybe for cost reasons or changing security compliance reasons that you need to host pieces of it on your own infrastructure via n8n’s self-hosted version. Well if you’ve architected the “joints” with HTTP Request & Webhook as the connective tissue between all your workflows, migrating portions of the app is as simple as recreating that chunk of functionality in n8n and then switching the URL of the HTTP Post in Make. If you’ve instead built using the tool’s proprietary connection method, your job at this point will require some untangling. Maybe you’ve had the amazingly good problem of gaining so much traction that you’re now hitting scaling issues and you need to convert portions of the app to some more performant compiled library, same thing – you’re going to have to unravel all those proprietary connection points at that point and convert them to HTTP requests so why not just do it that way from the start?
Reason #2: Chokepoints in developing and debugging
The other advantage of using HTTP Request & Webhook as the connective joints of your workflows is building and debugging becomes far easier. Using tools like Postman (or Bruno if you prefer OSS) and Pipedream Requestbin give you ability to see exactly what’s being sent and received between the “joints” of your application and enables you to isolate and emulate requests. This has numerous benefits:
- Faster to test things – you don’t need to re-run pieces of the workflow each time if you already know their inputs/outputs up to that point.
- Parallelize development amongst multiple team members. You can agree on the HTTP Post message format that you’re passing to the Webhook and that becomes a veritable “rail spike” that you can both independently build towards (one team on the workflow that generates it and one on the workflow that consumes it).
- Save money on unnecessary workflow executions.
This last one ^^ can translate to significant savings depending on what your application is doing. Let me give you a real example of this from the Stone Soup codebase:
Here are screenshots of two workflows I made in n8n that handle our smart intro functionality amongst members:
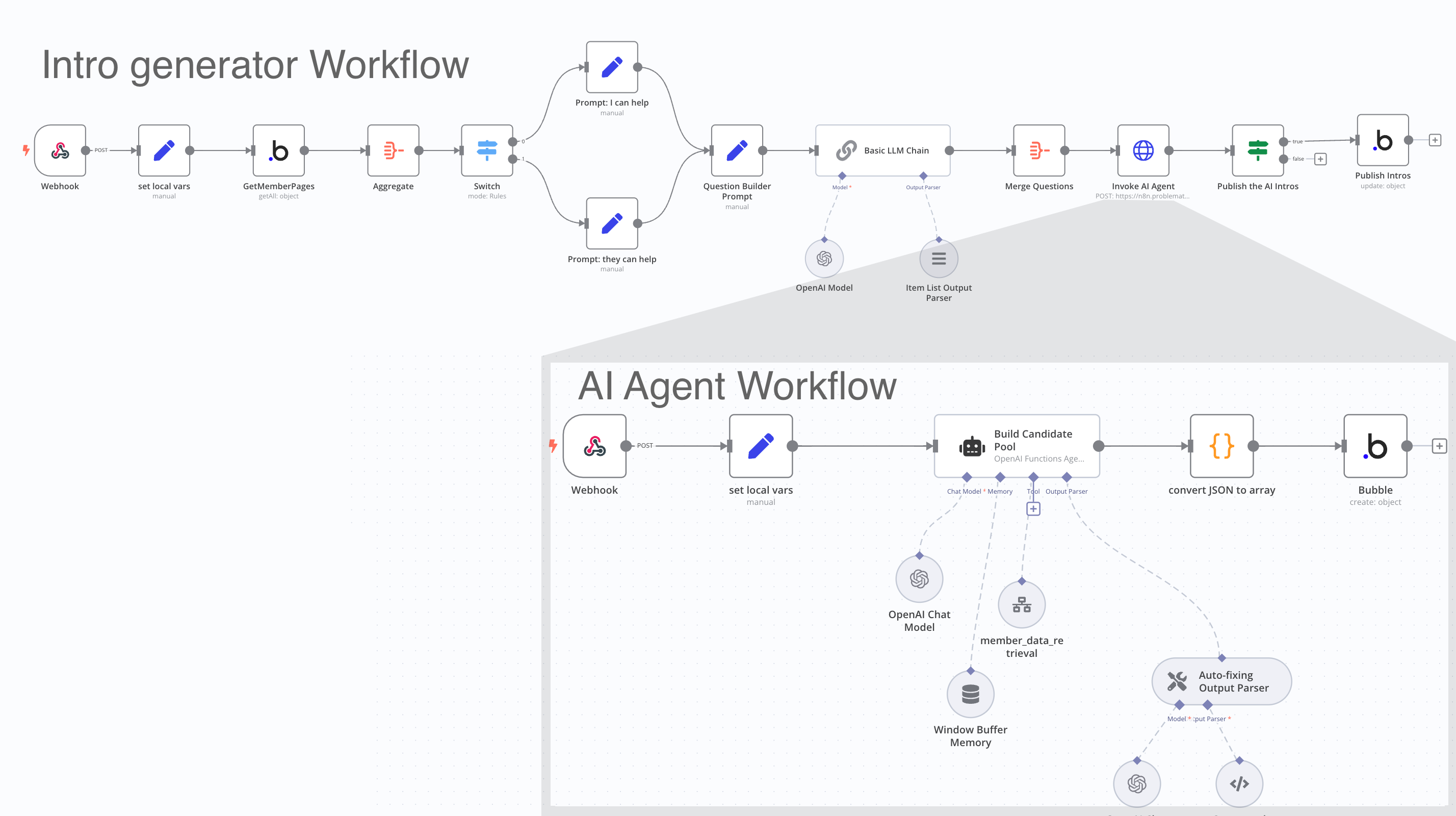
The “Intro Generator” workflow can be triggered by someone in the app requesting a new set of intros, automatically upon bulk import of a set of new members or anytime someone fills out an intake survey.
You can see how it develops a set of questions then invokes the “AI Agent” workflow to formulate the intros. In developing these I probably had to run this sequence over a hundred times to work out all the details. But once I have the master chain figured out up to the point where I’m invoking the AI Agent, I don’t need to keep re-running it. I can simply preserve the JSON data that’s being passed into the Webhook at that point and use a tool like Postman or Bruno to manually invoke that secondary workflow each time. This “chokepoint” technique of development is very useful especially in a workflow like this that’s invoking the OpenAI LLM each time – it can save you from wasting on senseless API calls and platform credit expenditures.
How do you create these chokepoints?
The easiest way I’ve found is to use a combination of two tools: one to capture the initial HTTP Post and then once you have it, the other to be able to send it manually. Here’s how to do it:
Part I: get the JSON
- Go to pipedream.com/requestbin and create a new RequestBin. This is an endpoint sitting out there that you post to and it inspects the contents of the request.
- Grab the URL of the RequestBin you just setup, open the HTTP Request node, paste it in place of the webhook of the secondary workflow and hit the Test button.
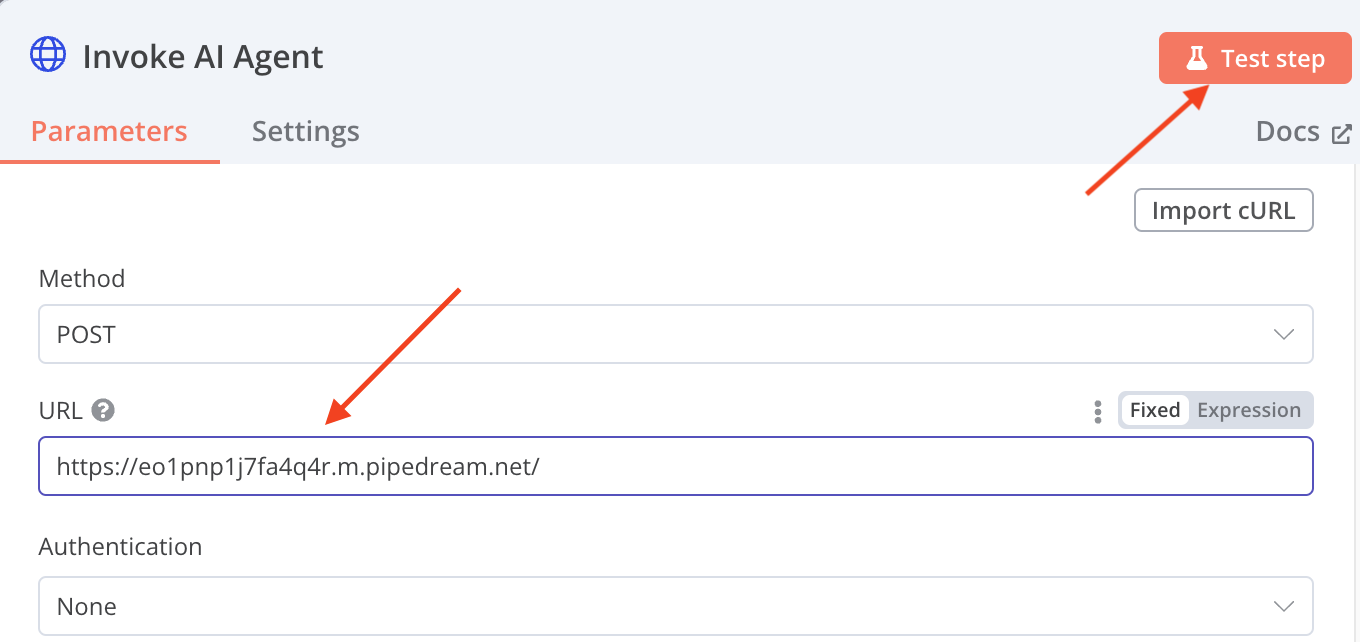
- Go back to RequestBin and you should see a new event. Click into it and scroll down and it should show the captured request. Copy the body of the request:
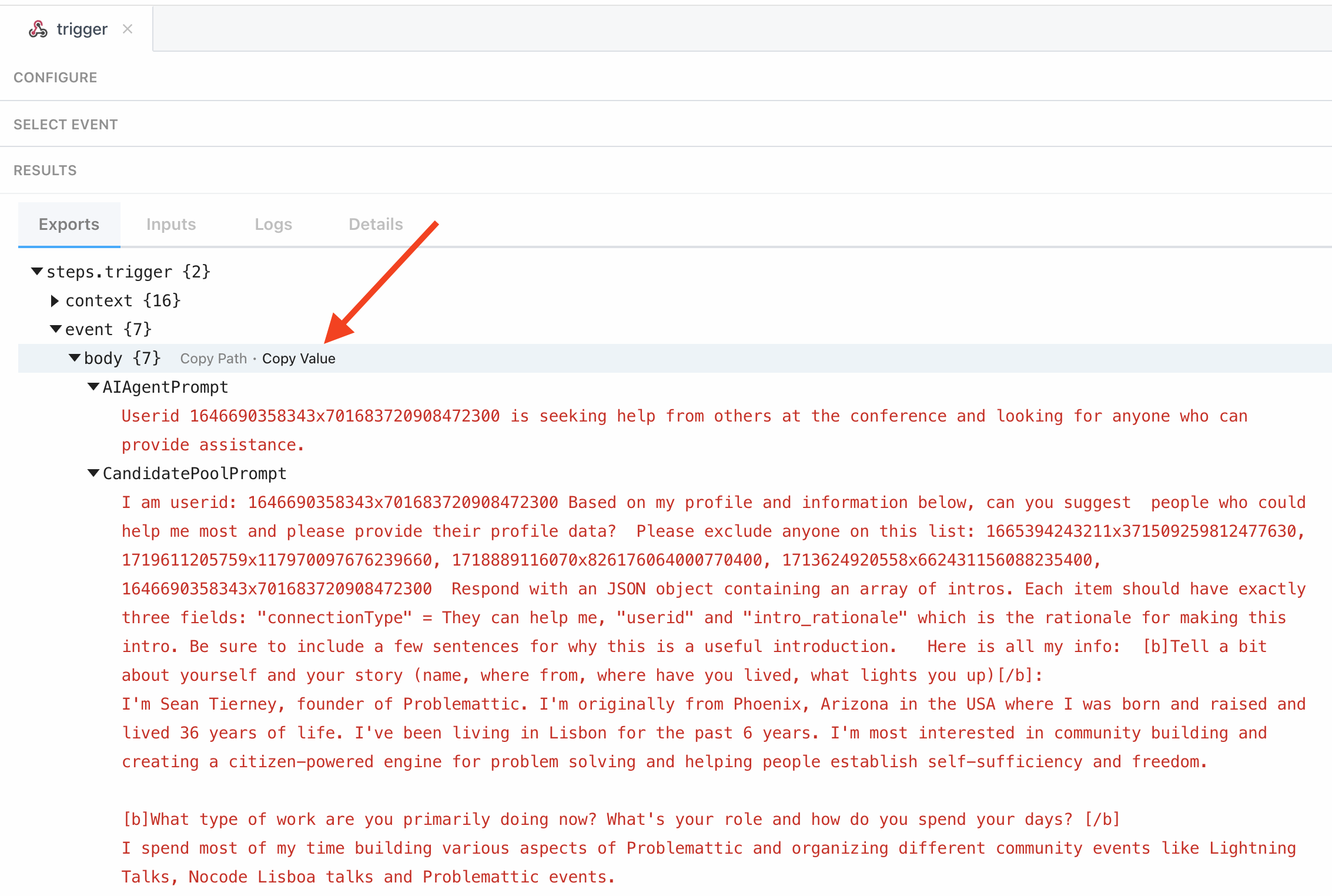
- Lastly, paste the contents into a text file. It should be a valid JSON object and keep this as we’re going to need it for the next part.
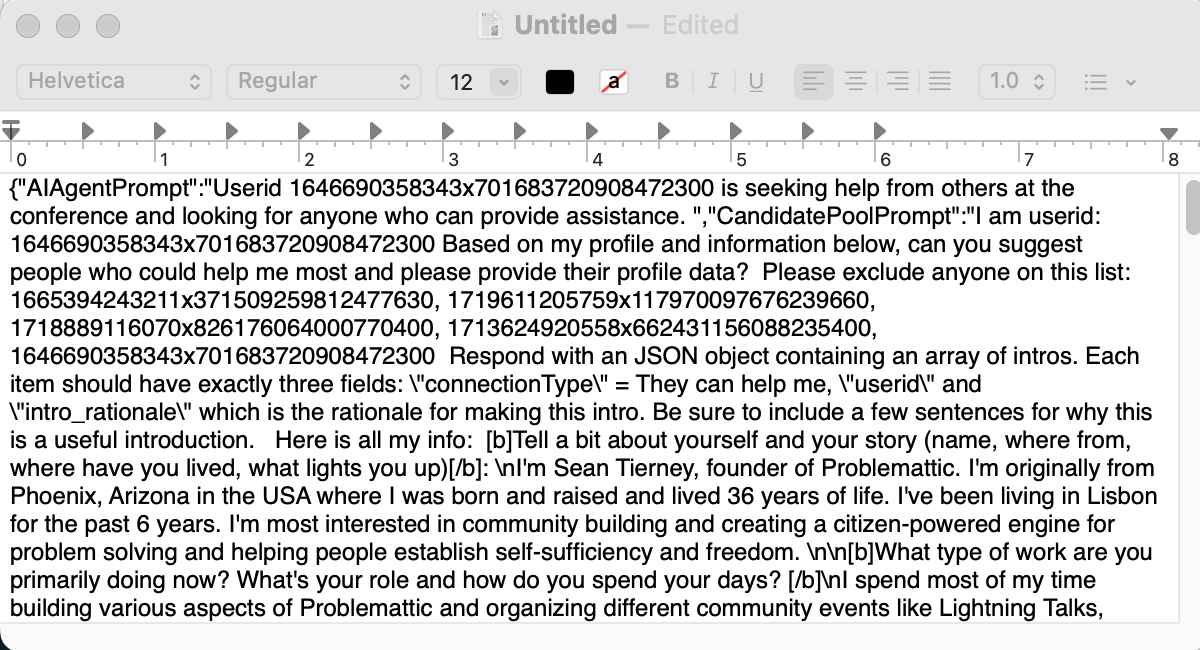
Part II: emulate the request
So now you have the exact body of the HTTP Request. Nice. Next we’re going to perform the role of that node by manually posting the contents to the webhook that initiates the secondary workflow. Open Postman and do this: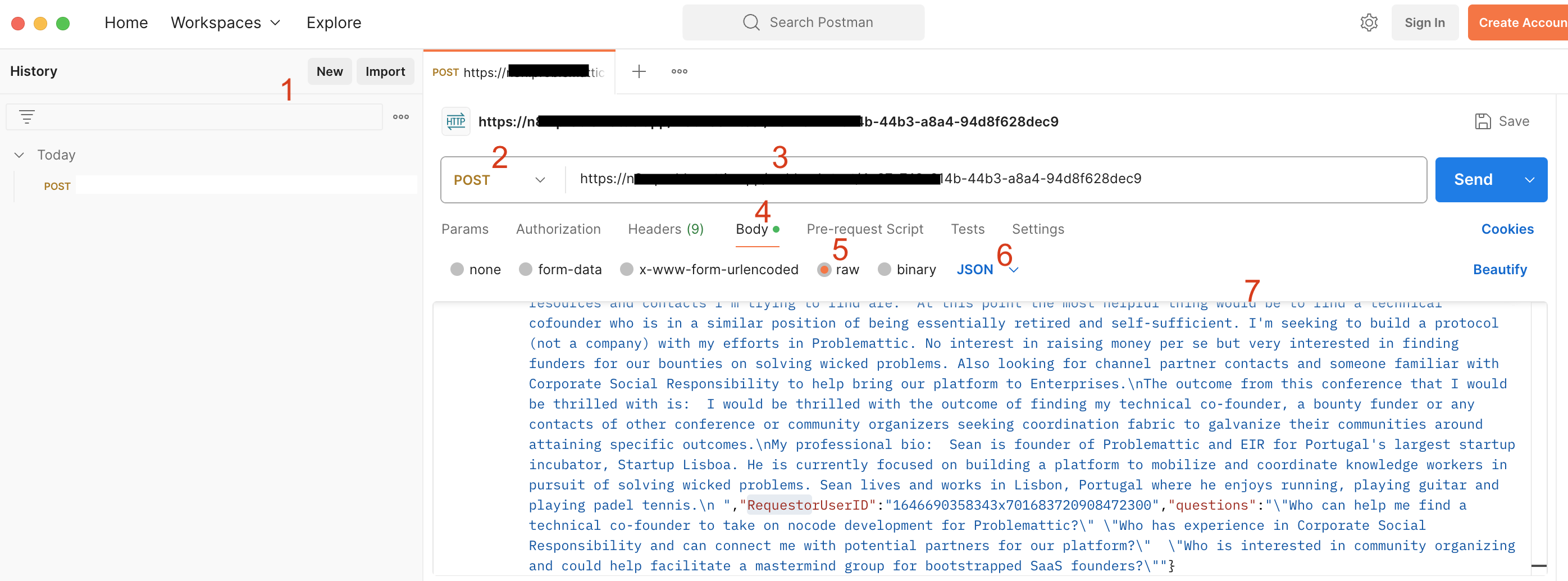
-
- create a new HTTP request
- switch it to type = POST
- paste in the URL of the endpoint of the webhook that initiates your secondary workflow
- go to the Body section
- switch it to “Raw”
- switch it from Text to JSON
- Paste in the JSON you stored in the text file.
- and lastly click the blue button to send the request
Assuming it worked you should have just successfully performed the role of the HTTP Request node and triggered the secondary workflow with the exact same data.
Now you needn’t run that first workflow when building/debugging. You can simply send the request via Postman and continue working on your secondary workflow.
Considerations
If you’ve made it this far you now know the value of breaking up complex workflows into a more object-oriented style approach and you understand advantages of doing it via the HTTP Request / Webhook method. The final bit to go through here are the considerations around performance and security. Depending on the platform your using you may see a performance hit with this approach as it’s kicking off additional processes to handle the web post and receive hook. Unless you’re doing insane throughput of requests IMO the advantages far outweigh the hit in performance penalty. For security, you just need to make sure you’re using some form of authentication with the Webhook to ensure it can’t be maliciously manipulated by a bad actor. I recommend enabling Basic Auth on all your webhook requests. Each platform has its own way of handling this but in most cases you can use a global variable or a credential that is valid systemwide to make this trivial to implement. You’ll need to remember to pass whatever authentication credential you choose via Postman or Bruno when you’re developing.
Conclusion
You now have a new super power. Modular design once you understand the pattern can be applied agnostic of the tool. For instance everything we’ve just learned here can be applied towards creating reusable elements in nocode platforms like Bubble and Webflow. You just have to start thinking in terms of identifying the variance and encapsulating it.
Someone recently asked this question in a Discord group I’m in:

And my response:
These are the books I recommended here and here if you want to learn more about programming principles from a purely conceptual level and how they can help you in your daily work in a nocode environment.
Good luck with modularizing your workflows. If you found this post helpful, consider sharing it with a friend.
Thanks for reading. Could you answer a few questions below? This is incredibly helpful for understanding my readers and helps me create better content. thanks so much. -Sean

The post is great. Very informative. I love the examples, and also, that it isn’t too dumbed down. It gives specific ideas and information. Thanks so much!